Conversational AI that speaks India.
Build WhatsApp and voice bots in major Indian languages. Low-latency, India-hosted inference with native Indic models, not English models with a translation layer.
Why existing solutions fall short
Your users don't speak English
Many high-volume Indian WhatsApp workflows run in Hindi, Tamil, Telugu, or other regional languages. English-first models miss the mark.
Latency kills conversations
Voice bots need sub-second response. Cross-border routing adds noticeable latency that breaks the conversational experience.
Scaling costs explode
High-volume WhatsApp bots burn through tokens fast. USD billing with forex markup makes unit economics unsustainable at scale.
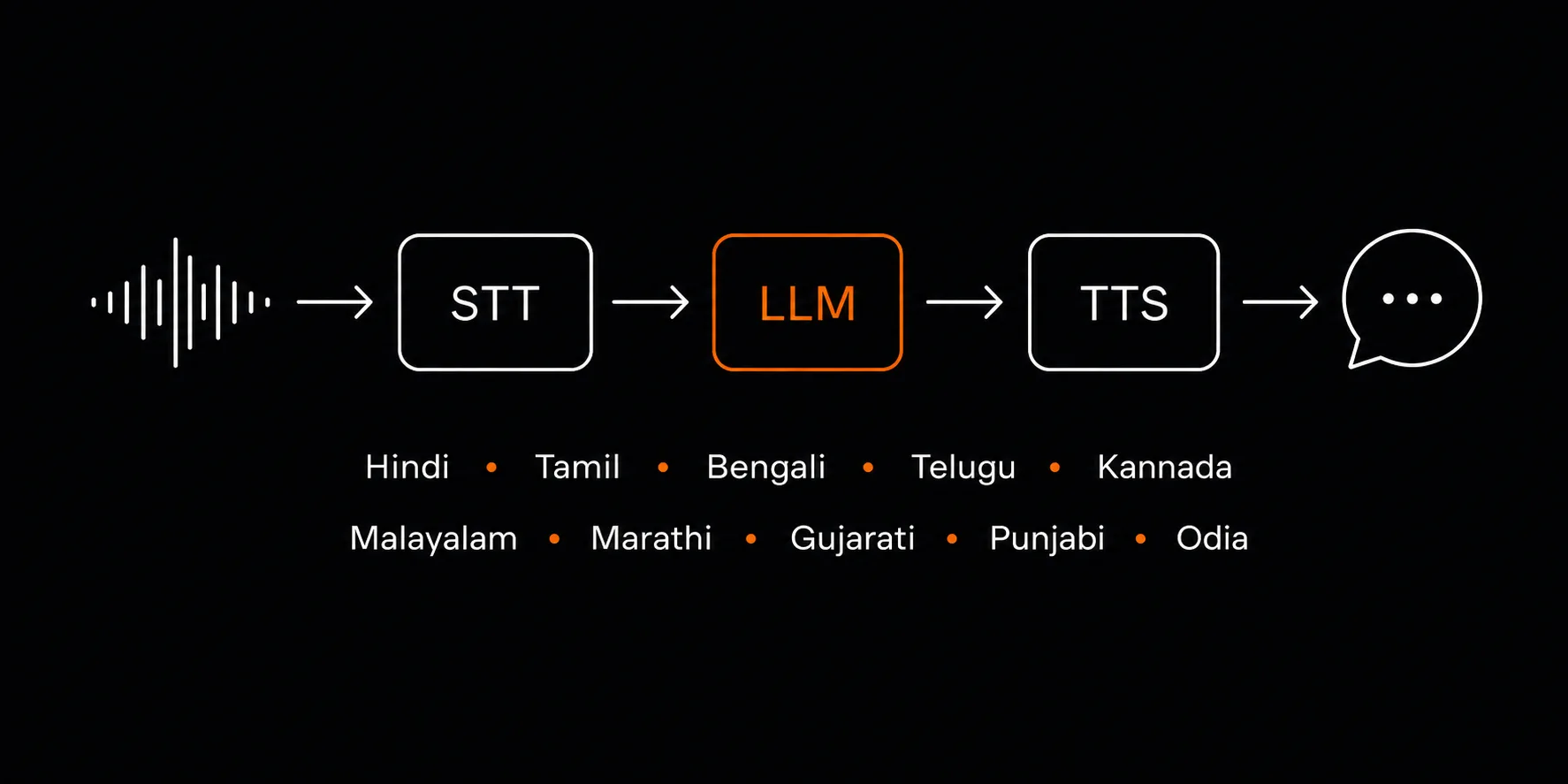
Purpose-built for Indian voice and chat
Full stack of Indic-native models (STT, LLM, and TTS) accessible via a single OpenAI-compatible API.
Indic Speech-to-Text
Whisper and IndicConformer models tuned for Indian languages. Handles accents, code-mixing, and noisy audio.
Whisper Large V3 (Hindi-tuned), IndicConformer
Indic Text-to-Speech
Natural-sounding voice synthesis in major Indian languages. Multiple voices per language.
Indic Parler TTS, AI4Bharat VITS
Multilingual Chat LLMs
Indic-native and multilingual models trained on Indian languages, not just translated from English. Native understanding of context and idiom.
Sarvam-30B, Krutrim-2, Qwen3-8B
Low-Latency Inference
India-hosted GPUs mean lower network latency for Indian users. Economy models optimized for high-throughput serving.
Economy tier: 7B-12B models
Built for scale
Major Indian Languages
Models that understand Hindi, Tamil, Telugu, Bengali, Marathi, Gujarati, Kannada, Malayalam, and more, including code-mixed variants.
Streaming Responses
Server-sent events for real-time token streaming. Essential for voice bots that need to start speaking before the full response is ready.
High-Volume Pricing
Economy tier models designed for chatbot scale. INR billing so your unit economics work at 100K+ conversations/month.
India Data Residency
Inference processing designed to stay in India. Critical for BFSI, healthcare, and government WhatsApp deployments.
Build bots that speak major Indian languages
Indic STT, TTS, and multilingual chat models, all on India-hosted infrastructure.
Request Early Access1We review your request within 48 hours
215-minute scoping call to understand your workload
3Sandbox API key to test with your actual prompts